【DeepSeek之后,国产大模型在文本这条赛道上又加了一码】
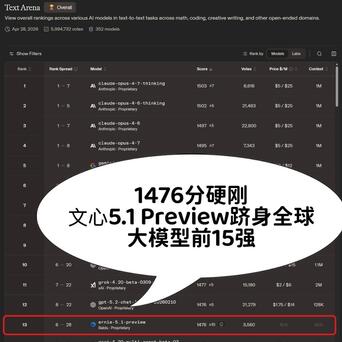
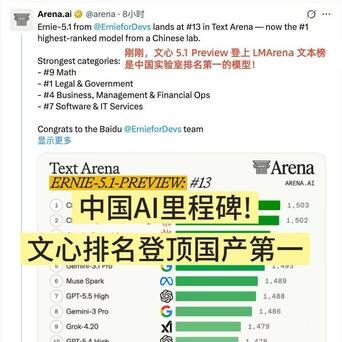
最近看到 LMArena 更新了文本榜单,有个排名让我盯着看了很久——文心 5.1 Preview 拿了国产第一,把 GPT-5.5、DeepSeek-V4-Pro 都甩在了身后。
这个时间点很巧,DeepSeek-V4 刚发布不久,热度正高。很多人在讨论它的代码能力、推理能力,但我注意到的却是另一件事:即便强如DeepSeek-V4,它最核心的形态依然是文本模型。这不是巧合,而是大模型领域一个被讨论了很多次、但每次都会被新热点掩盖的底层逻辑——文本能力,才是大模型的基本盘。
为什么这么说?你可以把文本能力理解为大模型的“母语”。代码生成看着是在写程序,但本质上是对自然语言指令的精确理解和结构化表达;复杂推理看着是在一步步推演,但推演的每一步都依赖语言作为思维的载体;哪怕是多模态理解,最后也要落到文本描述、文本对齐上来。可以说,大模型的大部分能力,都是从文本能力这根树干上长出来的枝丫。文本底子不够扎实,上层能力迟早会遇到天花板。
所以当我在LMArena文本榜上看到文心5.1 Preview的成绩时,第一反应不是“它超越了谁”,而是“中国模型在最重要的那条赛道上,又往前拱了一步”。1476分,榜单前十五名里唯一的国产模型,而且在榜单上是在DeepSeek-V4、GPT-5.5这些最新发布、最受瞩目的模型前面。这种排位的变化,比单纯的名次数字更能说明问题。
说实话,文心这两年给我的印象一直比较沉稳,每次更新都挺有准头。业内有一个判断我挺认同:文心这轮能快速迭代,根子在于文心5.0在底层训练范式上做了一次实打实的创新。它提出了一项叫“多维弹性预训练”的技术,简单说就是一次训练,能产出多种规模的模型。这种思路跟“一个模型练一版”的传统方式完全不同,直接把研发效率拉上了一个台阶。
文心5.1 Preview就是这种技术路线下的阶段性成果。更有意思的是它的成本数据——以业界同规模模型大约6%的预训练成本,把基础效果做到了领先。相当于别人花100块钱才能干成的事,它用6块钱就做到了。这个数字背后,是技术路线的代际差异,不是靠堆算力能追平的。
目前文心5.1 Preview已经在百度千帆模型广场开启邀测,面向企业用户和开发者开放体验。我去看了一下,申请路径已经打通,准备上手试试实际表现。另外还有消息说,文心 5.1可能会在5月的Create 2026百度AI开发者大会上正式亮相。预览版在榜单上已经能冲到国内第一了,正式版会交出什么答卷,这个悬念留得我心里挺痒的。
不管怎样配资正规网站,文本能力这块最重要的阵地,国产模型现在确实站住了,而且是用一种更聪明的方式站住的——不只拼参数,更拼底层创新的效率。

富深所提示:文章来自网络,不代表本站观点。
- 上一篇:配资之家官网 还得是华强北,给iPhone Air打孔、塞卡槽,成了一条产业链
- 下一篇:没有了
相关文章



热点资讯